Concept¶
The major target of audiomate is to provide a generic way to read/write different corpus/dataset formats or read specific corpora/datasets. So, independent of the dataset, one can use the same code to access the data.

Corpus structure¶
To represent any corpus/dataset in a generic way, a structure is needed that can represent the data of any audio dataset as far as possible. For this purpose the following structure is used.
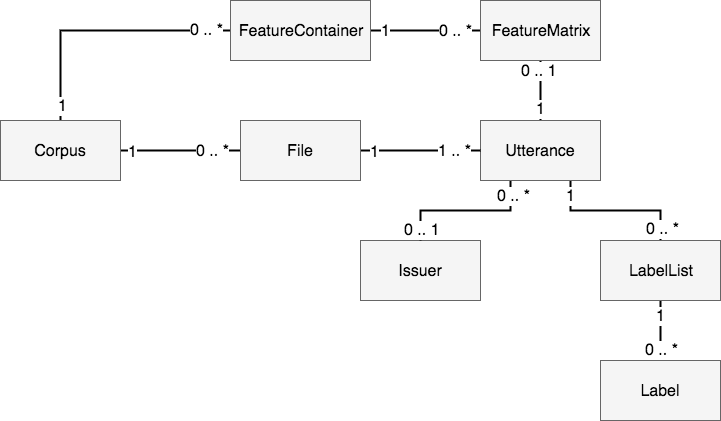
- Corpus
- Represents a dataset/corpus.
- File
- The file is basically a reference to a physical file that contains any kind of audio data.
- Utterance
- An utterance represents a segment of a file. It is used to divide a file into independent segments. A file can have one or more utterances. The utterances are basically the samples in terms of machine learning.
- Issuer
- The issuer is defined as the person/thing/… who generate/produced the utterance (e.g. The speaker who read a given utterance).
- LabelList
- The label-list is a container for holding all labels of a given type for one utterance. For example there is a label-list containing the textual transcription of recorded speech. Another possible type of label-list could hold all labels classifying the audio type (music, speech, noise) of every part of a radio broadcast recording.
- Label
- The label is defining any kind of annotation for a part of or the whole utterance.
- FeatureContainer
- A feature-container is a container holding the feature matrices of a given type (e.g. mfcc) for all utterances.
- FeatureMatrix
- A matrix containing the features of a given type for one utterance.