Corpus Structure¶
To represent any corpus/dataset in a generic way, a structure is needed that can represent the data of any audio dataset as good as possible. The basic structure consists of the following components.
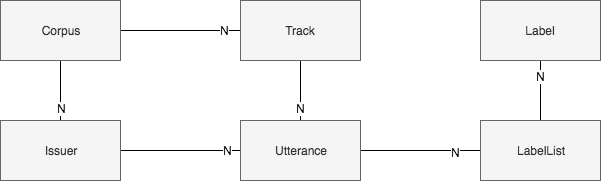
Corpus¶
The Corpus is the main object that represents a dataset/corpus.
Track¶
A track is an abstract representation of an audio signal. There are currently two implementations. One that reads the audio signal from a file and one that read the audio signal from a HDF5 container.
Utterance¶
An utterance represents a segment of a track. It is used to divide a track into independent segments. A track can have one or more utterances. The utterances are basically the samples in terms of machine learning.
Issuer¶
The issuer is defined as the person/thing/… who generate/produced the utterance (e.g. The speaker who read a given utterance).
An issuer can be further distinguished into different types. The current implementation provides classes for speaker (for spoken audio content) and for artists (for musical content).
LabelList¶
The label-list is a container for holding all labels of a given type for one utterance. For example there is a label-list containing the textual transcription of recorded speech. Another possible type of label-list could hold all labels classifying the audio type (music, speech, noise) of every part of a radio broadcast recording.
Label¶
The label is defining any kind of annotation for a part of or the whole utterance.
FeatureContainer¶
A feature-container is a container holding the feature matrices of a given type (e.g. mfcc) for all utterances. A corpus can contain multiple feature-containers.